 My GopherCon 2023 talk, Build Your Own Distributed System Using Go, has been published to YouTube.
My GopherCon 2023 talk, Build Your Own Distributed System Using Go, has been published to YouTube.
It was a great conference, and I appreciated the opportunity to share some lessons on designing, developing, and operating modern distributed systems.
You can check out the video here.
 rqlite
rqlite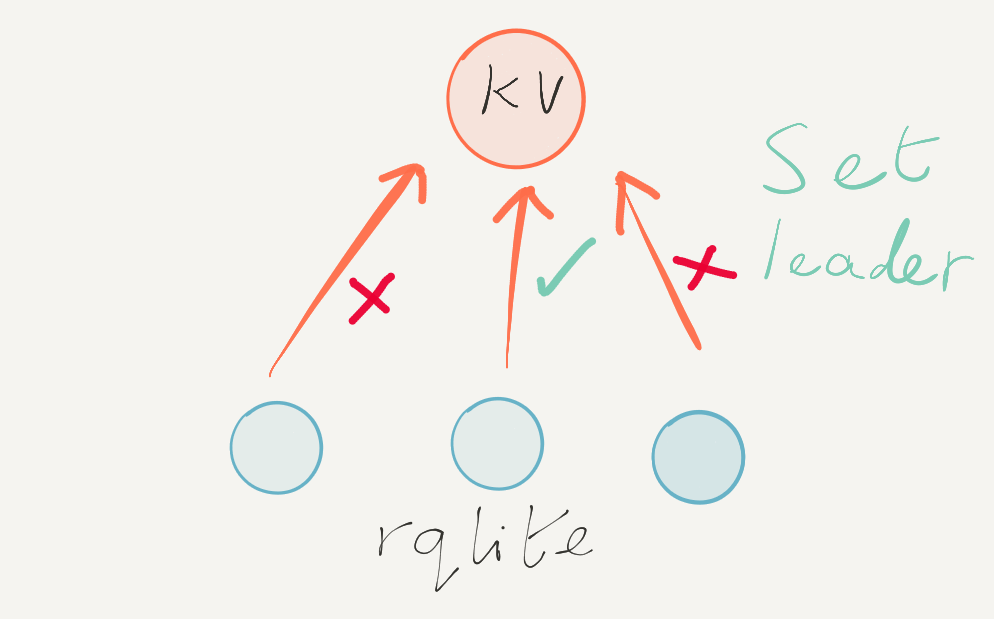

 There is a popular image out there, among the general public, that small startups — particularly small software startups — are a hotbed of technical innovation, constantly creating new technology. But is it true?
There is a popular image out there, among the general public, that small startups — particularly small software startups — are a hotbed of technical innovation, constantly creating new technology. But is it true? If you work in the logging, monitoring — or even
If you work in the logging, monitoring — or even 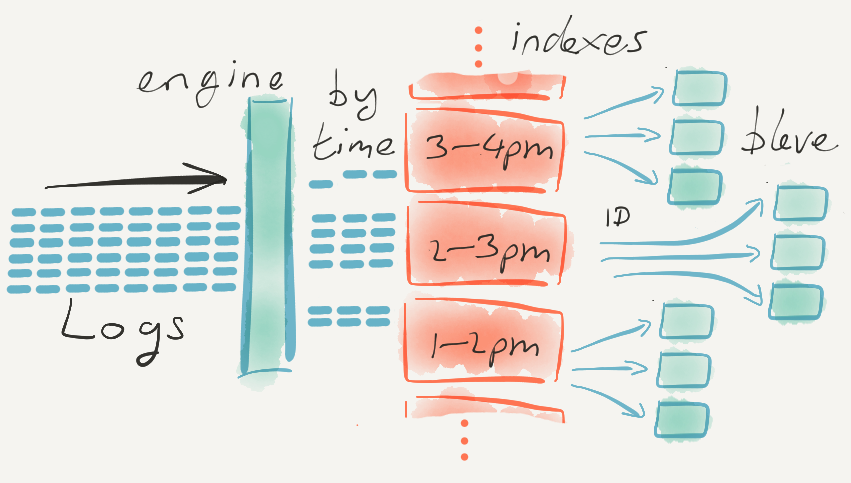
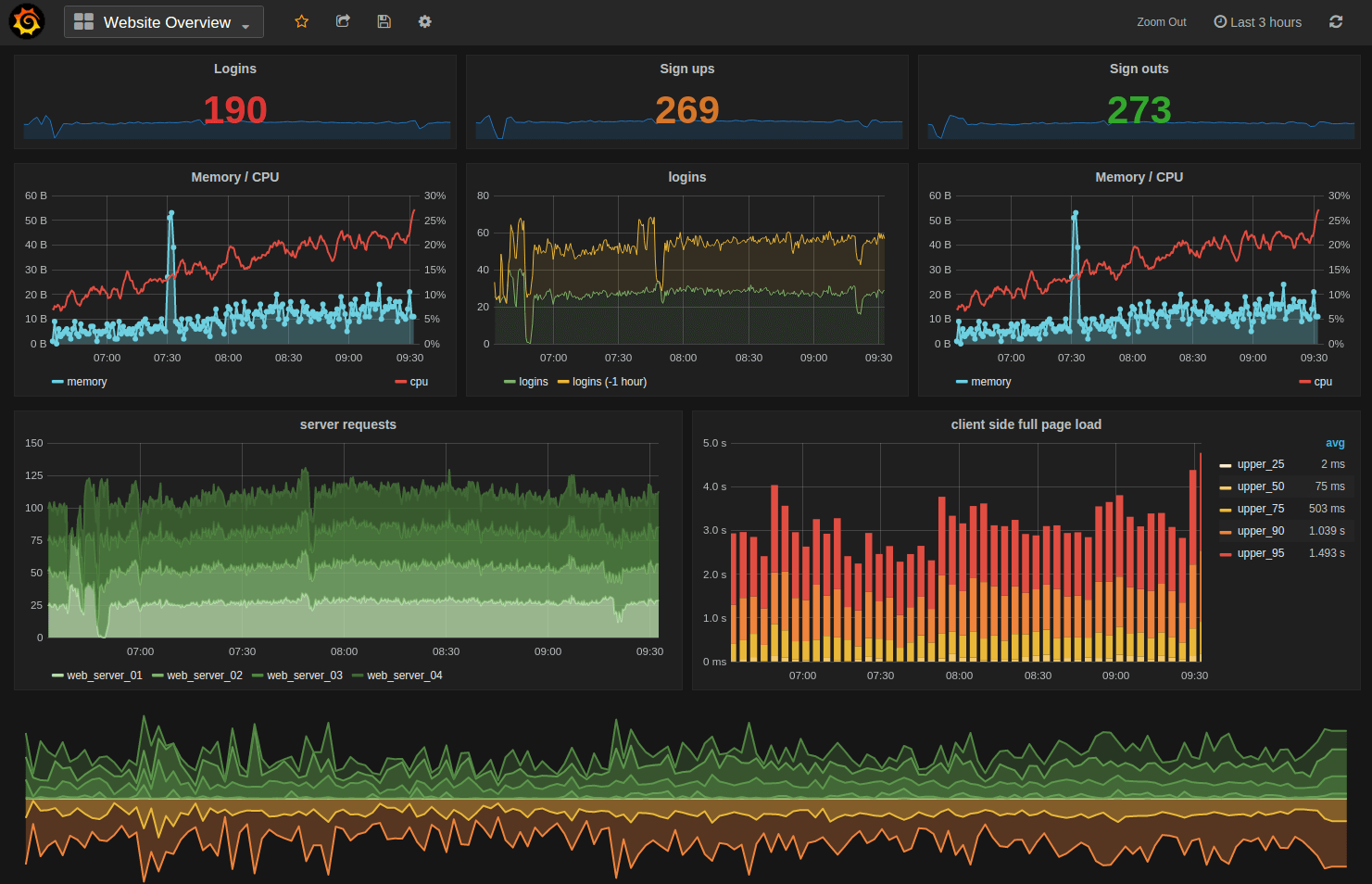 Monitoring — the measurement of your system, the gathering of telemetry, and alerting when it behaves anomalously — is
Monitoring — the measurement of your system, the gathering of telemetry, and alerting when it behaves anomalously — is