rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. v6.0.0 is out now and makes clustering more robust. It also lays the foundation for more important features.
is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. v6.0.0 is out now and makes clustering more robust. It also lays the foundation for more important features.
What’s new in 6.0?
6.0 multiplexes multiple logical connections between rqlite nodes using the existing Raft inter-node TCP connection. This multiplexing existed in earlier versions, was removed, but has been re-introduced in a more sophisticated, robust manner.
This new logical connection allows Followers to find the Leader in a more robust and stateless manner, when serving queries that require the client to contact the Leader. It also uses Protocol Buffers over this logical connection, leading to more robust, extensible code.
The evolution of a design
Inter-node communication in an rqlite cluster has evolved over the years, and it’s interesting to see the 3 design patterns in context. What do I mean by inter-node communication in this case? I mean the transmission of information specific to rqlite itself between cluster nodes, but not the Raft-specific communication between the Hashicorp code.
The first thing to understand is that each rqlite node exposes two network interfaces — first, a Raft network address managed by the Hashicorp Raft system, and second, a HTTP API which clients use to query the SQLite database. From the client’s point-of-view, the Raft network address is an implementation detail, it’s only there for clustering functionality.
While each node knows the Raft network address of every other node thanks to the Hashicorp Raft implementation, each rqlite node must also learn the HTTP URL of the Leader, so it can inform client code where to redirect queries. And since the Leader can change and even be completely replaced, each rqlite node must have up-to-date information regarding the Leader HTTP URL at all times.
The core challenge is that this information about HTTP URLs is not something the Hashicorp Raft handles intrinsically, because the Raft layer only knows about Raft network addresses. The HTTP URLs are an rqlite concept, not a Raft concept.
Therefore it’s up to the rqlite code to deal with redirecting clients to the Leader’s HTTP URL, if servicing a client’s request requires contact with the Leader (not all queries involve the Leader, but most do).
How this is done has evolved over time.
Pattern 1: Clients must search for the Leader
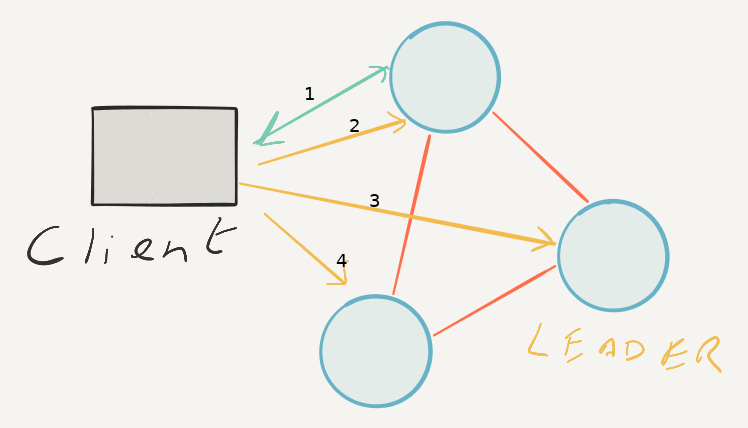
Before version 3.x, rqlite nodes returned the Raft network address of the Leader to the client, if the requested operation could only be served by the Leader (assuming the node itself wasn’t the Leader). This forced the client to check all other cluster nodes, to see which one had the relevant Raft address, and then redirect the query itself to that node’s HTTP API URL.
While this meant the rqlite code was much simpler than later versions, this approach only worked if the client knew about every node in the rqlite cluster, or always knew which node was Leader. This was not very practical, especially if nodes in the cluster changed or failed. There was no surefire, yet simple, way the client code could be informed of those changes, so clients could effectively lose touch with clusters.
Pattern 2: Nodes communicate HTTP API URLs via Raft consensus

By version 3.0 it was clear that rqlite Follower nodes needed to return proper HTTP redirects. But the question then became how would Follower nodes know the HTTP URL of the Leader, at all times, regardless of any changes that happen to the cluster?
Versions 3.x, 4.x, and 5.x used the Raft consensus system itself to broadcast this information. When a node joined the cluster it would commit a change to the Raft log, updating the configuration that mapped Raft network addresses to HTTP API URLs. Thanks to the Raft consensus system every node always knows every other node’s Raft network address so, in theory, each node could learn every other node’s HTTP API URL via this mapping. And therefore every node knew the Leader’s HTTP API URL, even across Leader changes.
This design worked well for a long time, but had some shortcomings. One possible problem was what to do if a node joined the cluster, but then failed to update its HTTP API URL mapping (for whatever reason). It could happen since it was two distinct changes to the Raft system, but was very unlikely. But if it did, the cluster could need significant manual intervention before it could recover.
Over time other bugs were discovered which showed this approach wasn’t robust when cluster membership changed regularly. This design also required operators to explicitly remove failed nodes from the cluster configuration, or the Raft-address-to-HTTP-URL mapping could become stale. Ultimately this design meant extra state, in addition to the SQLite database, was being stored via Raft. And more state means more chance for bugs.
So while this approach worked well enough for years for versions 3.x, 4.x, and 5.x, by version 6.0 a better way had been identified. So instead of fixing the bugs, the design was reworked to render the bugs moot.
Pattern 3: Followers query the Leader on demand

In version 6.0, a Follower contacts the Leader on demand, when it needs to know the Leader’s HTTP API. And critically it contacts the Leader over the Raft TCP connection, a connection that must always be present anyway — without that connection the node is not part of the cluster, and the cluster has bigger issues. So this new design doesn’t introduce any new failure modes, though it does introduce an extra network hop.
This type of design is also stateless, and even if reaching out to the Leader to learn its HTTP API URL fails, that failure happens at query time — meaning the client can be informed and the client can decide how to handle it. Most likely the client can simply retry the request, if the error is transient.
You can find further details on the design on 6.0 in the CHANGELOG.
What’s coming in future releases?
This new design and implementation makes it much cleaner to implement the following, upcoming features.
Connection pooling
6.0 does result in more network traffic between nodes, if a Follower is continually queried. It’s not a large amount of network traffic, but connection pooling between nodes will help reduce connection setup time.
Transparent request forwarding
Today if an rqlite Follower receives a request that must be served by the Leader, it will return HTTP 301. Now, with a more sophisticated inter-node communication mechanism, future releases will allow Follower nodes to query the Leader directly on the behalf of the client and return the results directly to the client. This will make using the CLI, and client library coding, simpler, and make the cluster much easier to work with — allowing rqlite to serve queries much more transparently.
Better Kubernetes support
During 6.0 development, I got some great assistance from the team at Sosivio. They found some bugs in the 5.x series, and provided best practise advice on how rqlite can be changed to work better on Kubernetes. Those changes may feature in future releases.
Next steps
Download version 6.0, and try out the more robust clustering — and look out for new features in future releases.