rqlite![]() is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine and Raft for distributed consensus. Release 7.0 is out now and introduces the first wave of new Node Discovery and Automatic Clustering features.
is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine and Raft for distributed consensus. Release 7.0 is out now and introduces the first wave of new Node Discovery and Automatic Clustering features.
What’s new in 7.0?
Before we get into the distributed system design, let’s take a look at what features 7.0 has introduced.
In this release rqlite can use either Consul or etcd to perform Node Discovery and Automatic Clustering. In each case rqlite uses the key-value functionality offered by each system, and critically the ability of each to perform a test-and-set operation on a single key. Consul calls this a Check-and-Set, while etcd refers to it as a Compare operation within a transaction.
Before 7.0, rqlite did support an AWS Lambda-based Discovery Service, but it was somewhat primitive, insecure, and crucially a bespoke solution. And if users chose not to use any Discovery mechanism, nodes simply had to know the network addresses of other nodes a priori. This works well for many situations, but made more dynamic deployments difficult.

7.0 also moves away from using original BoltDB and now uses the etcd fork, bbolt. This brings rqlite into line with what Consul uses for its Raft subsystem.
A new Discovery and Auto-clustering design
The Discovery design is straightforward, and the implementation defines a Go interface any key-value store must implement. This allows other systems to support rqlite Discovery functionality if needed.
Let’s look at an example of forming a 3-node cluster. Remember, rqlite uses the Raft consensus algorithm under the hood. Therefore each cluster has a single Leader, and possibly 1 or more Followers. The key goal of this Discovery and auto-clustering design is to get one node — and only one node — to decide it should be Leader.
Each node starts off without any state, except the network address of the key-value store. Crucially nodes do not need to know the network addresses of any others nodes that will be part of the cluster. Each node attempts to write its address to the key-value store, via a check-and-set operation.
However, only one node will succeed, indicating that it can proceed to self-elect as Leader. The other two nodes will then back off.

The nodes that failed to write their network address to the key-value store then poll the key-value store until the address of the Leader appears.
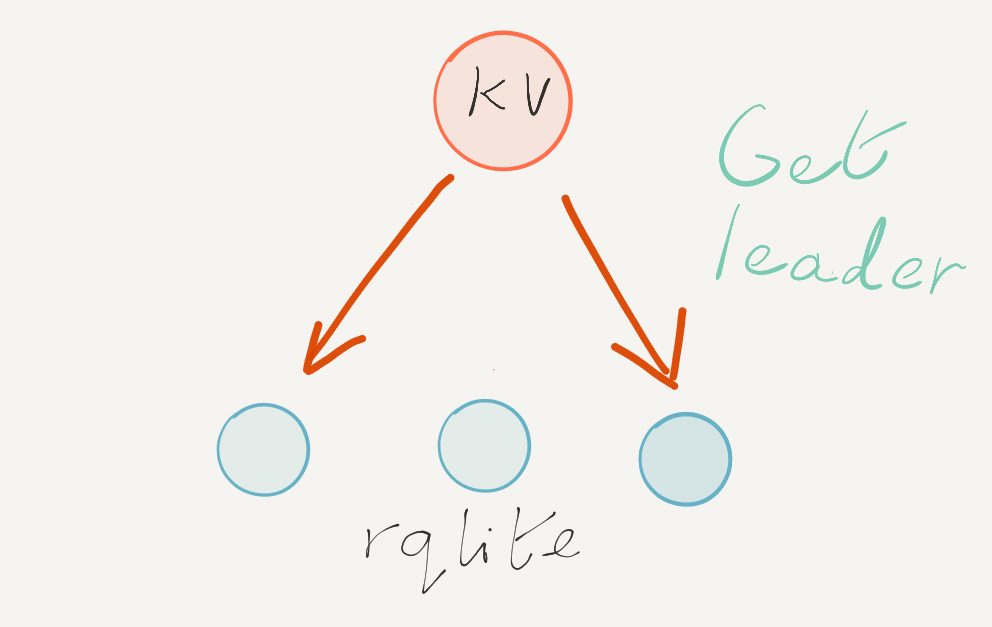
Once the two non-Leader nodes learn where the Leader is, each can then join with the Leader, forming the three-node cluster. The Leader also periodically updates the key-value store with its address, allowing other nodes to join later. And if the Leader ever changes, the new Leader will start updating the key-value store with its new address, which it does via an unconditional set-key operation.

It’s important to note that the key-value store is not a single point of failure, once the cluster has formed. While it’s helpful if the key-value store remains available, any node can join with cluster, at anytime, simply by being explicitly passed an address of any other node in the cluster. But once formed the rqlite cluster does not depend on the key-value store. In other words the fault-tolerance and high-availability offered by rqlite does not depend on the key-value store.
Load testing
Since 7.0 is a major release, and rqlite uses a new database for Raft storage, 7.0 has been load tested to ensure no performance issues crept in. There will be a follow-up blog post on the results, but the testing shows performance remains the same as previous releases, and memory usage is steady.
What’s coming in future releases?
7.0 introduces this simple, yet very useful, key-value based node discovery. Upcoming releases of rqlite will provide more sophisticated Node Discovery and Automatic clustering.
Kubernetes and Headless Service support
A Kubernetes headless service is an ideal way for rqlite nodes to find each other. By deploying such a service on Kubernetes, and having a set of rqlite Pods register with the service, the rqlite nodes can bootstrap a cluster. Because bootstrapping a cluster is an atomic operation in the Hashicorp Raft layer (on which rqlite is built) each Pod will attempt to bootstrap, but only one Pod will succeed — and then Leader election will take place as normal.
Another nice characteristic of using a headless service is that the service also acts as a way for rqlite clients to find the resulting rqlite cluster.
DNS-based discovery
DNS SRV records are a standard way to communicate one or more address for where a given service is located on the network. Similar to a Kubernetes headless service, once a set of rqlite nodes can learn the network addresses of all nodes in the cluster the nodes can bootstrap a cluster.
Next steps
If you’re interested in learning more about the design and implementation of rqlite, check out the presentation I recently gave to Carnegie Mellon.
So download version 7.0, and try out the new node discovery and automatic cluster — and look out for new features in future releases.