This is a post following up on my Monitorama Baltimore 2019 talk.
Logging and Monitoring systems — Observability Systems, if you prefer — often seem to struggle to meet the needs of their users.
Why is this? I think part of it is due to the challenges intrinsic to developing these systems. And it’s not just a technical challenge — it’s a product challenge.
Data at very large scale
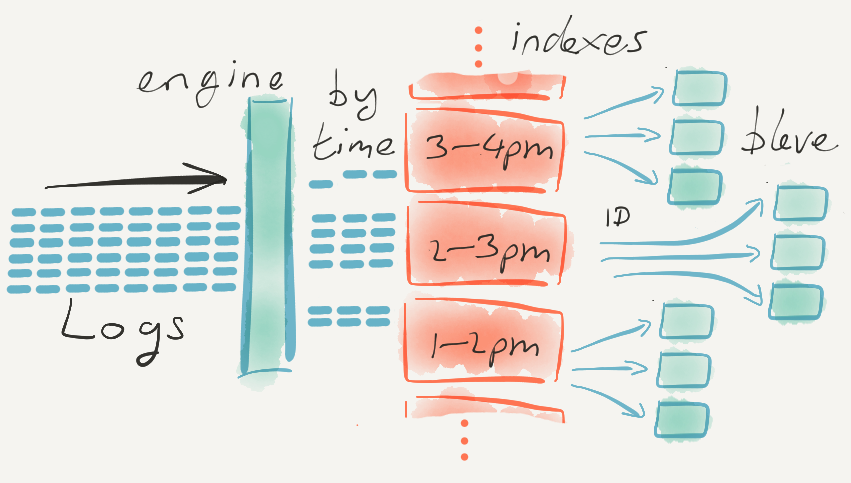
The first challenge is that the data is often at very large scale. After all, these systems are built to handle data generated by computers — often very large scale infrastructure — and computers never tire, they never stop, they are always emitting signals in form of logs, time-series, and traces.
Of course, computers do stop emitting sometimes — when they go down. But that is when you need all that log and time-series data the most.
Highly heterogeneous data
Logging and Monitoring systems — particularly Logging — must handle data that is highly variable. When it comes to logs, the data is often structured and unstructured, sometimes including special semi-structured patterns such as stack traces, and key-value pairs.
Time-series data usually has variable, and sometimes high, numbers of dimensions, with many of those dimensions exhibiting high-cardinality.
Sometimes these systems even have to handle binary data. All this heterogenity forces the developers of these systems to make difficult trade-offs.
Unrelenting demand for low-latency – at both ends of the system
All of us in Computer Science know how to build systems that can read in enormous amounts of data really quickly, and make it available for fast querying some time later — we have techniques like sequential writes to disk, post-processing to add indexes, roll-ups, and so forth. But all that processing takes time, adding delays between when the data is received, and when it can be effectively queried.
We also know how to read in relatively small amounts of data, and make it queryable practically instantaneously. For example we have data structures that can make searching very fast.
Both of those are solved problems.
What makes building Observability systems a particular challenge is that the systems must meet both requirements simultaneously. They have to ingest all the data large computer infrastructure are emitting, and make that data available for queries almost immediately. Because during an outage you need to get your systems back online now — and understanding what just happened a few moments ago is often key.
So building these systems means building for users who demand performance at both ends of the system.
And no one wants to pay for it
Often the first complaint from people deploying or operating these systems is that they are too expensive. And if you try to sell these systems, it’s often surprisingly difficult, and people expect a lot at low cost, or even for free.
Yet anyone who has tried to build (and rebuild) these systems — as I have for almost 10 years — will find out why they are expensive. Observability Systems are really hard to implement well, particularly when they are to be run at scale, and in a performant manner.
There are even more subtle effects
There is also another pernicious — and darkly humorous — force at work. The development teams that build these systems — the teams I have been part of — we build software for people who are often in a bad emotional state when they are using our software.
This fact seeps into the teams, putting an extra stress on the developers and Product Managers. We see more than our fair share of bugs filed by people in stressed and pressured situations.
The bugs are often not pretty — and who can blame the user? Discovering a bug in the Monitoring system itself, in the middle of dealing with your own outage, is never a good experience.
Of course, we keep on building
I’m sure there are other factors to consider — but it is remarkable how many products there are in this space, considering its difficulty. I think it’s because it’s a fascinating and challenging area to develop, and perhaps one of the best ways to learn.
The field of logging & auditing is as open and bizarre as Cybersecurity. The lack of a standard in the industry is indicative of an absent desire to put forth an effort. It’s not complicated. Standardize output to a unified format, create repeatable parse generators, stay away from elastic search, and you’ll have a unified industry.