rqlite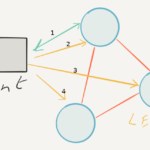 is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. v6.0.0 is out now and makes clustering more robust. It also lays the foundation for more important features.
is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. v6.0.0 is out now and makes clustering more robust. It also lays the foundation for more important features.
Continue reading rqlite 6.0: the evolution of a distributed database design


 It was April 9th 2016, and I tagged
It was April 9th 2016, and I tagged