![]() Search is everywhere. Once you’ve built search systems, you see its potential application in many places. So when I came across bleve, an open-source search library written in Go, I was interested in learning more about its feature set and its indexing performance. And I could see immediately one might be able to shard it to improve performance.
Search is everywhere. Once you’ve built search systems, you see its potential application in many places. So when I came across bleve, an open-source search library written in Go, I was interested in learning more about its feature set and its indexing performance. And I could see immediately one might be able to shard it to improve performance.
What is sharding?
Anyone who has worked to understand or improve the performance of information storage-and-retrieval systems, such as databases and search engines, quickly becomes acquainted with the concept of sharding. Sharding means partitioning a data set into smaller pieces such that read and write load can be spread across more compute and storage resources. It’s an effective technique to maximize disk throughput, particularly on multi-core machines. Many systems including InfluxDB (which I work on), elasticsearch, and MySQL, all use sharding for performance and replication.
Sharding comes with a cost however. When a query is executed multiple shards must be accessed, which usually means more files must be opened. Results from each shard may need to be merged, and that is not trivial. But the performance benefits usually outweigh the costs.
The nature of bleve
bleve users can choose from multiple storage engines, and it uses BoltDB by default, which is also used by the latest version of InfluxDB. Each bleve index is a BoltDB database, but this means only a single writer can be writing to the database at one time. This means the indexing performance is going to be limited by how busy the code can keep that writer. I’m sure this is not the only limitation within bleve, but it will be one.
bleve indexing performance is also very dependent on the number of documents indexed in each transaction — the batch size. One reason is again BoltDB, which performs much better when large amounts of data are written in one transaction.
Performance testing
The source code for this testing is available on Github.
First, some details about the host machine and data set. The machine was a high-end 64-bit desktop machine running Kubuntu 13.04. It has SSDs, 16GB of RAM, and with 8 Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz cores. The test data was a set of 100,000 short text documents, and each document was about 200 bytes in size — think tweets and some metadata associated with each tweet.
A word on GOMAXPROCS. I set this to 8. It’s important to do so, since bleve makes use of an “analysis worker queue” and leaving this at 1 results in very little improvement as the shard count is increased. See this post on the mailing list for more details.
During testing the source documents were not stored, just indexed. bleve does allow the documents to be stored however, which is quite useful. Terms vectors were also disabled. You can find the full indexing settings in the test source code.
Initial testing of indexing performance, into a single bleve index, was not that impressive, when one considers the host machine. I used atop to keep an eye on disk usage, and the disk wasn’t as busy as I hoped. I increased the batch size, and while it did improve performance, I could not saturate disk. So next I decided to see if sharding would increase indexing performance. Specifically, instead of using a single bleve index to process my test data, I would create multiple bleve indexes i.e. shards, split the data into as many partitions as there were shards, and then index each data partition in parallel.
Coding all this wasn’t too difficult — you can check out the code here. The program simply partitions the test data across all shards, executes indexing for each shard in a separate goroutine, and times how long it takes for all indexing to complete.
Let’s take a look at the results — click on the graphic below for a better view.
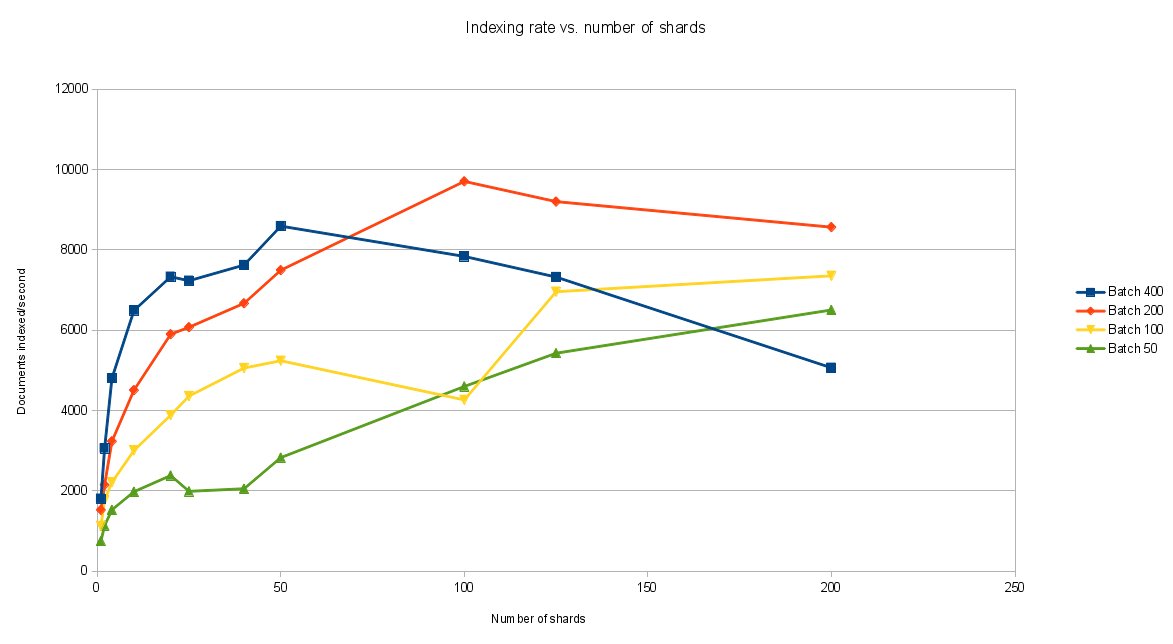
The graph show many interesting features. Clearly both batch size and sharding increase throughput. However, unlike batch size increases, the disk easily became saturated as the number of shards increased, which is what I wanted to see. At around 50 shards the disk started showing as 100% busy with writes. After that performance starts to decrease for larger batches. But this shows that performance improvements can be achieved using simple sharding.
(An earlier version of this post showed had an indexing bug and the results where not valid. This has been fixed here).
You can see the raw numbers here, which were outputted directly by multiples runs of the test program.
Next steps
Working with bleve is very interesting, and it’s really nice to have a Go solution for text search. Since bleve supports multiple storage engines, a logical next step would be to re-run testing with LevelDB, which it also supports. But I really like the simple pure-Go build process that results when BoltDB is used.
In addition, the ability to store source documents in the underlying storage engine is very useful, specifically through the API call SetInternal. I fully expect performance to decrease significantly once source documents are stored, however.
Finally, bleve supports index aliases — making multiple bleve indexes seem like a single bleve index. This is very useful for performing searches across multiple shards.
Many thanks to the bleve programmers — a fun piece of software to use.