 rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. 6.6.1 improves handing of some error cases.
rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. 6.6.1 improves handing of some error cases.
You can download the release from GitHub.
rqlite is a lightweight, open-source, distributed relational database written in Go, with SQLite as its storage engine. 6.1.0 enables new SQLite options including JSON1 support and the DBSTAT table. It also supports proper concurrent database reads for in-memory databases, and write requests no longer block those reads.
You can download the release from GitHub.
rqlite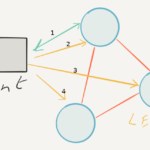 is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. v6.0.0 is out now and makes clustering more robust. It also lays the foundation for more important features.
is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. v6.0.0 is out now and makes clustering more robust. It also lays the foundation for more important features.
Continue reading rqlite 6.0: the evolution of a distributed database design
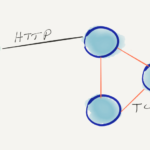 It was April 9th 2016, and I tagged my first official release of rqlite — two years after I actually started coding it. Since then there has been 58 releases, 277 closed issues, 416 closed pull requests, 32,785 insertions, 1954 deletions, and 100 files have changed.
It was April 9th 2016, and I tagged my first official release of rqlite — two years after I actually started coding it. Since then there has been 58 releases, 277 closed issues, 416 closed pull requests, 32,785 insertions, 1954 deletions, and 100 files have changed.
Continue reading 7 years of open-source database development: lessons learned
![]() Thanks to Zac Medico, there is a new PyPI Project and package for rqlite. You can find it on the PyPI website.
Thanks to Zac Medico, there is a new PyPI Project and package for rqlite. You can find it on the PyPI website.
Version 2.1 is now available.