 This is the first in a series about core data structures and algorithms.
This is the first in a series about core data structures and algorithms.
Many explanations of data structures focus on the implementation — and that is very important — but I’ve always found some context makes it so much easier to learn. And the trade-offs between various data structures is one of the most interesting contexts you can study.
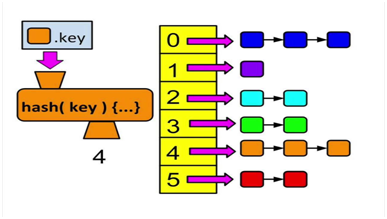
Hash tables — also known as maps or dictionaries — are great for associating an arbitrary item with another item, but in a space-efficient manner. For example if you have a body of text and wish to store the counts of each word, a hash table would be an excellent choice. In this case a word is known as the key and the count is the value.
Runtimes
Almost all important operations that take place on a hash table complete in a time independent of the numbers of items in the hash table. Insertion, deletion, and lookup — all finish in constant time, or O(1). And this is its great power.
Hash tables often speed up algorithms significantly. Anytime you need to continually check if a value is in a linear data structure (like an array), consider transforming that data set into a hash table — this is the classic space-time trade off algorithms make. Use more storage space, and get shorter — usually much shorter — runtimes.
Weaknesses
Hash tables suffer from one weakness however — the keys are not ordered. This makes it impossible to iterate over the keys in a specific manner. So if you wish to know, say, which key is first lexicographically, you have no choice but to check every key in the hash table. This prevents you running common search algorithms like a binary search, which could otherwise locate a key in logarithmic time.
The C++ STL does offer a data structure that has the interface of a hash table, but provides sorted key iteration — known as a map. However this is not really a hash map underneath, it’s actually implemented as a binary search tree. This means lookup, insertion and deletion are no longer constant time, but logarithmic.
It’s dictionaries all the way down
Hash tables are critical to programming — Python, in fact, is mostly a language built on hash tables. Hash tables, after arrays, are probably the most important data structure in computer science. In fact, the decision by the Go team to make it a built-in type is key factor in that language’s success. Anytime you need to associate arbitrary keys and values, hash tables are the data structure of choice.