Summary
You can download a PDF summary of my resume here.
I am an experienced Software Engineering Leader with a passionate interest in software and contemporary technology.
I have a solid track record of delivering quality software and shipping products on-time, in many diverse fields. I have led many software engineering teams as both a Technical Lead and Engineering Manager and know that successful software development is mostly about people, not computers. As part of my professional experience I have contributed to company blogs, given customer presentations, spoken at major industry conferences, and assisted with field testing.
My areas of expertise include:
- Building and leading software development organizations.
- Open source software development
- Designing and implementing SaaS platforms, with a particular emphasis on Observability platforms and products.
- Cloud computing infrastructure such as AWS and GCP.
- Web services development and API design.
- Data pipelines and analytics systems.
- Distributed systems, databases and search systems.
- Linux system software development (both kernel and user space).
- Embedded and real-time software.
- Digital video, audio, and MPEG systems.
Most recently I have built databases, analytics platforms, data pipelines and search systems using the Raft consensus protocol, Apache Kafka, Apache Storm, Zookeeper, and Lucene-based search technologies such as elasticsearch. I have also developed systems using technologies such as Django and express.js, relational databases, and NoSQL databases such as Cassandra.
I have a significant experience with C and C++, Python and Go. I also have notable development experience with JavaScript, node.js and some Java. Early in my career I developed deep experience with assembler.
I enjoy meeting customers, and found it provides excellent insight to future trends. I also consider mentorship an important and fulfilling responsibility of senior engineers like myself.
Open Source
I have created, and contributed to, various open-source software, including:
- Creator of rqlite, a distributed relational database, which uses SQLite as the storage engine, and Raft as the distributed consensus protocol.
- Ekanite, the syslog server with built-in search. It receives log data over the network, parses the log messages, and makes those messages available for search.
- Core developer of InfluxDB, an open-source distributed time-series database written in Go.
Professional Outreach
In addition to my personal blog, I have authored multiple corporate blog posts, most notably for Riverbed Technology, Loggly, InfluxDB, and Google Cloud. These posts described key details of the systems my teams designed and implemented, promoted new releases and features, and advocated improved industry practices.
I have presented at Meetups and conferences, spoken on industry podcasts and to academia, and have reviewed multiple technical books at the request of publishers, as well as acting as an official technical reviewer for such books as ElasticSearch CookBook Second Edition (2015) and Implementing Cloud Design Patterns for AWS (2015).
I have presented at AWS’ flagship conference — AWS re:invent. Titled Infrastructure at Scale: Apache Kafka, Twitter Storm & Elastic Search, I described the architecture of Loggly’s next-generation log aggregation and analytics Infrastructure, and runs on AWS EC2. The presentation was rated very highly by the attendees. It is available on YouTube here, and the slides are available here.
Experience
Pittsburgh, PA
Engineering Manager
2018 – Present
Part of the Google Cloud Platform (GCP) team, I manage multiple development teams, focused on designing and developing Operations Suite, the DevOps and Observability system for GCP.
Responsible for roadmap, vision, planning, team growth, and developing the managers and engineers within those teams. Ultimately accountable for successful execution by those teams, ensuring they deliver meaningfully towards business goals.
I work closely with Senior Operations Suite Engineering Management, Product Management, and the broader OperationsSuite Product Development team.
Percolate
San Francisco, CA
Director of Data Platform Engineering
2016 – 2018
Managed two teams of software developers across multiple locations, building the System of Record for Marketing. I was responsible for technical design and implementation, coding, hiring, effective execution, and quality. I worked closely with Product Management and the Executive management team on a day-to-day basis.
Analytics
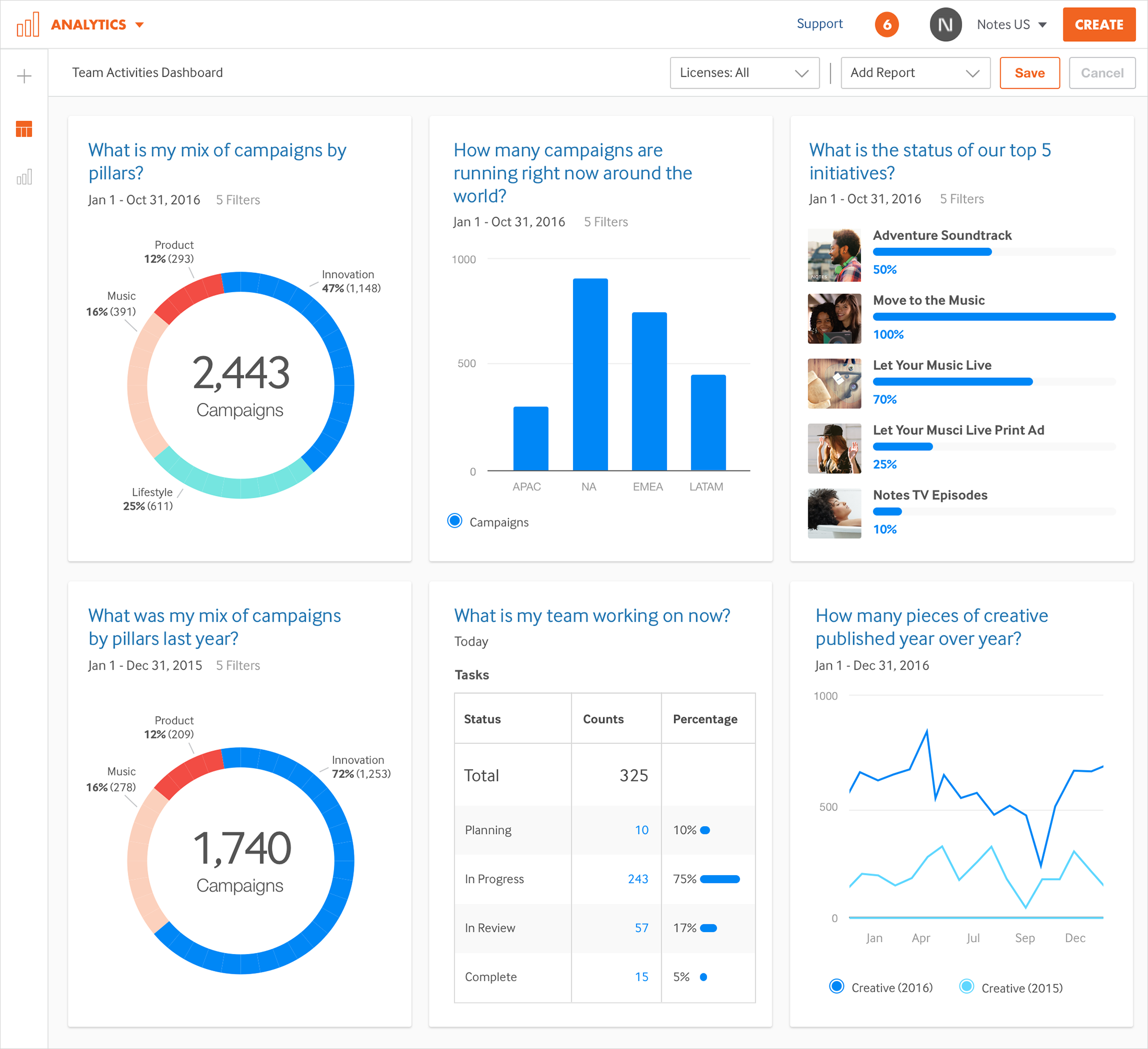
I led the team that designed and developed Percolate’s next-generation multi-tenant Reporting and Analytics platform. A key pillar of Percolate’s vision, it was successfully launched in February 2017, and remains in active development.
Data Platform and Integrations
I also led the teams responsible for Data Platform initiatives such as the Event Bus within Percolate, as well the team developing the next-generation service- and microservice-oriented architecture at Percolate.
The technologies in use by the Platform teams include Apache Kafka, Zookeeper, Elasticsearch, relational databases such MySQL and PostgreSQL, as well as AWS EC2, and DynamoDB.
InfluxData
San Francisco, CA
Director of Engineering
2014 – 2016
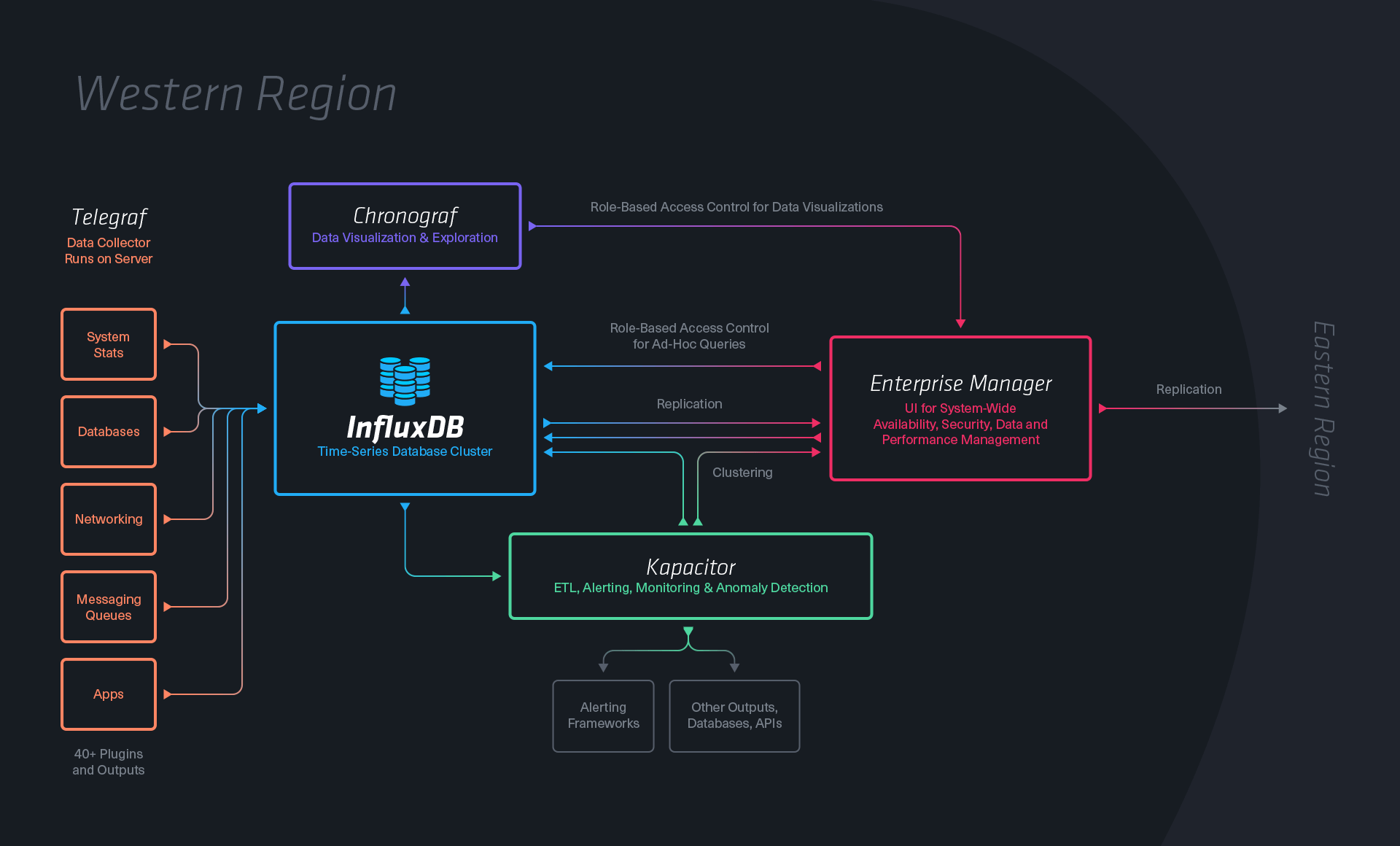
Key member of the team designing and developing InfluxDB, an open-source distributed time series database written in Go. InfluxDB is the core component of the InfluxData analytics platform for time-series data.
Core database development
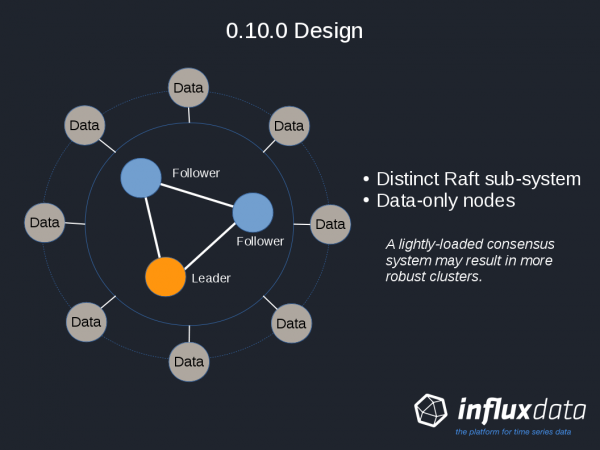
I was involved with design and development of all aspects of the system including data ingestion, clustering, distributed consensus, storage layer, query engine, and configuration and management. Joining when the database was at release 0.8, it had progressed to 0.10-rc1 by January 2016.
A strong advocate for coherent design, high-quality code, testing, and ensuring that the distributed development team is as effective and cohesive as possible.
I also maintained the build and CI system, the release process, as well as assisting with hiring activities.
Professional Services
I worked closely with the InfluxDB Professional Services team, providing technical deep-dives on product design and implementation, documentation reviews, and solution-brainstorming. I also directly assisted high-value customers with their InfluxDB deployments, including providing on-site support.
Open-source community
Placing high value on engaging the open-source community of developers, I was very active on the mailing list, and worked directly with them via Github. I also made multiple contributions to the corporate blog and the InfluxDB Meetup.
Jut
San Francisco, CA
Senior Software Developer
January 2014 – November 2014
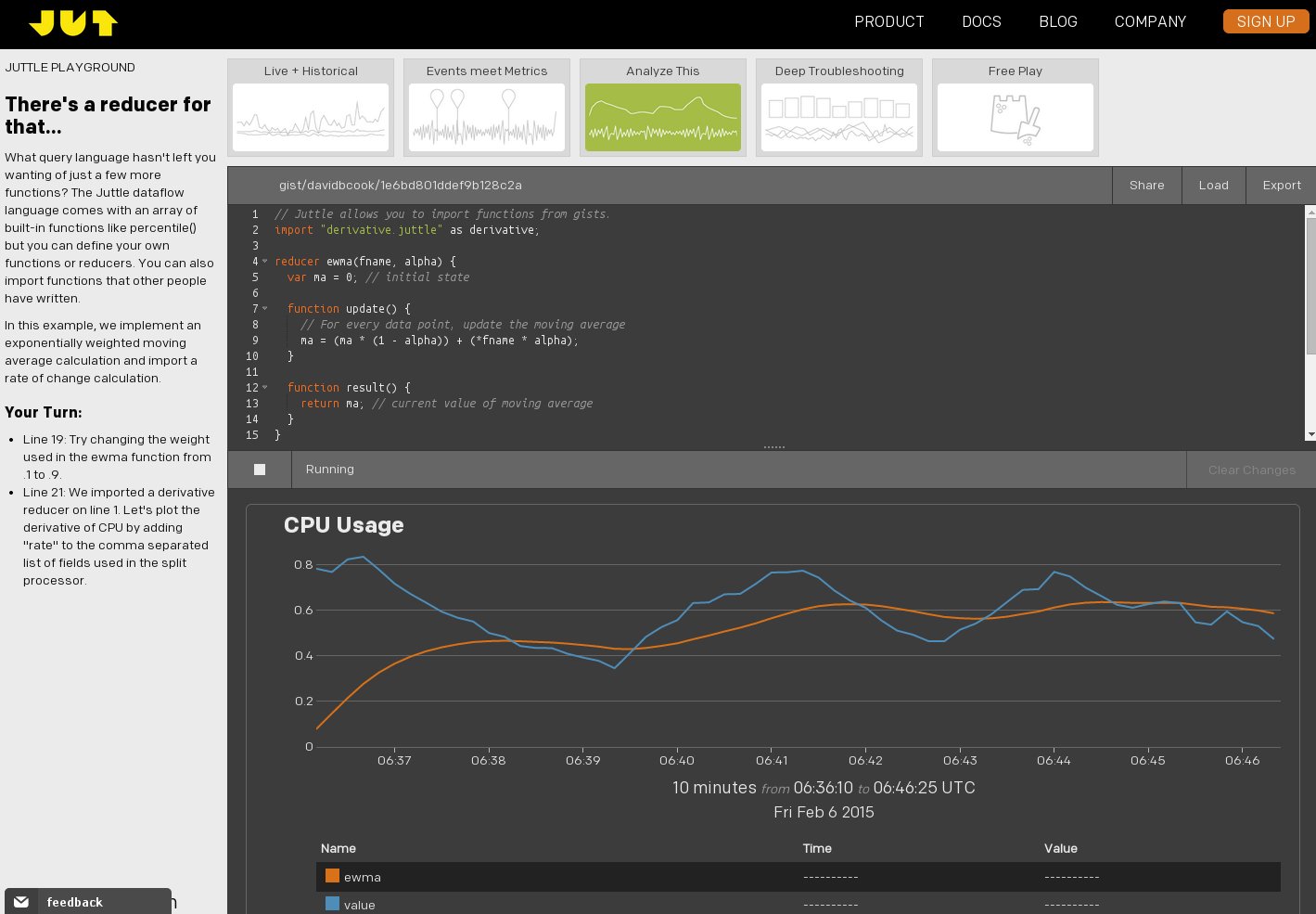
Senior member of the development team that designed and developed Jut’s IT Analytics solution. As a developer I was involved with full-stack node.js development, managed within an Agile-Scrum process, with daily stand-ups and twice-monthly planning meetings.
While at Jut I drove backend development of Jut’s AWS-hosted Account & Deployment management application, including design and development of a PostgreSQL-based system for the production site. It was implemented using node.js, making extensive use of express.js, and bookshelf.js. I also developed significant developer-level unit-tests using Mocha and worked closely with the QA team to ensure full testing was carried out.
To allow Jut to analyze and monitor customer usage of their product, I designed and developed a data-ingestion pipeline for clickstream and customer metrics. The system was deployed in AWS EC2, using chef, along with extensive monitoring using such tools as statsd and collectd.
Loggly
San Francisco, CA
Lead Backend Architect
2012 – 2014
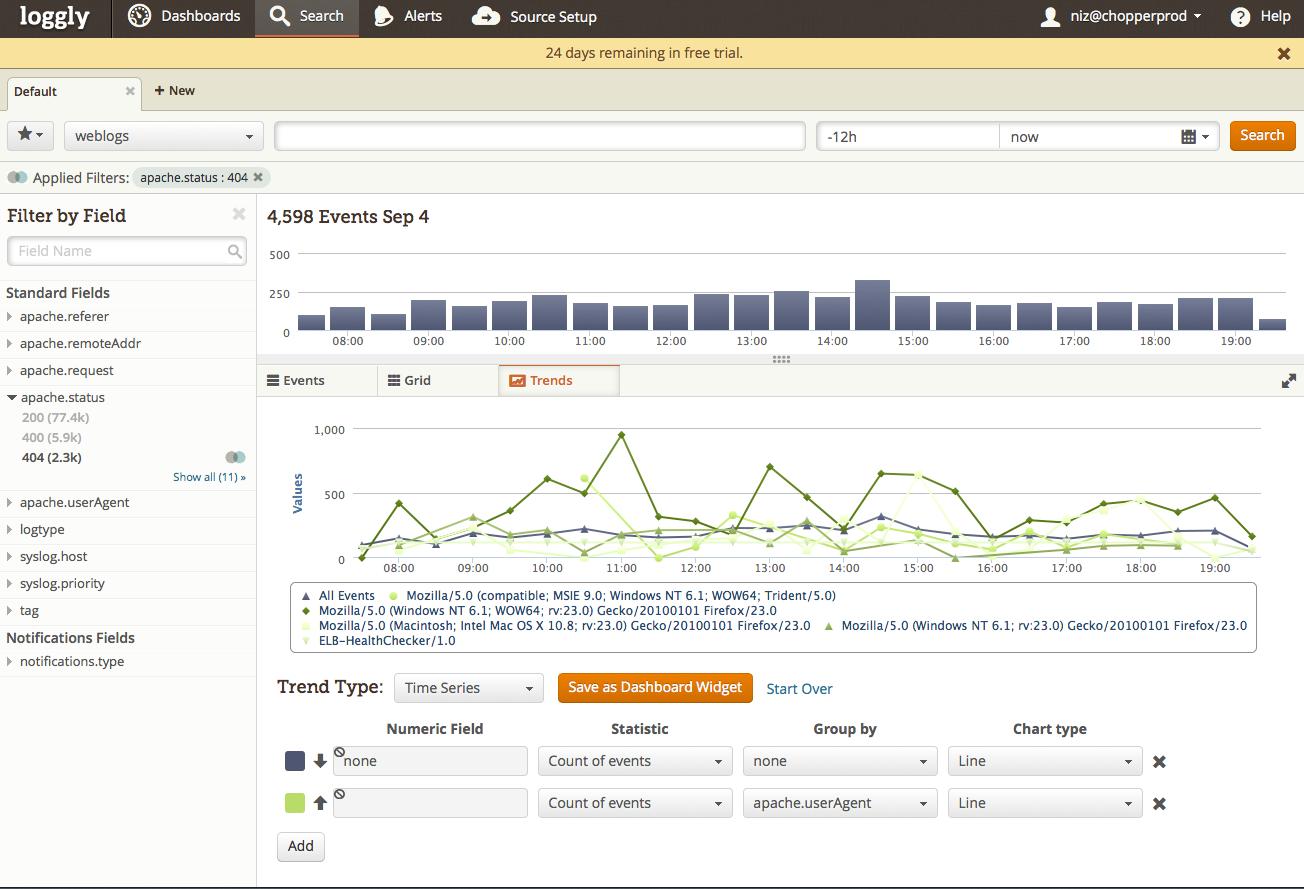
Loggly provides a cloud-based application intelligence solution for application developers and IT professionals. Loggly indexes application log data which can be used to troubleshoot, monitor and analyze customer usage.
Reporting directly to the CTO, I led the software infrastructure development team which designed and built Loggly’s 2nd generation Cloud-based, multi-tenant, distributed, Logging-as-a-Service SaaS platform. This team was responsible for design and implementation of the high-performance, fault tolerant, data collection, and near-real-time indexing and search infrastructure. Loggly’s 2nd Generation system was successfully launched in September 2013. It often indexed more than 1TB of log data per day after launch.
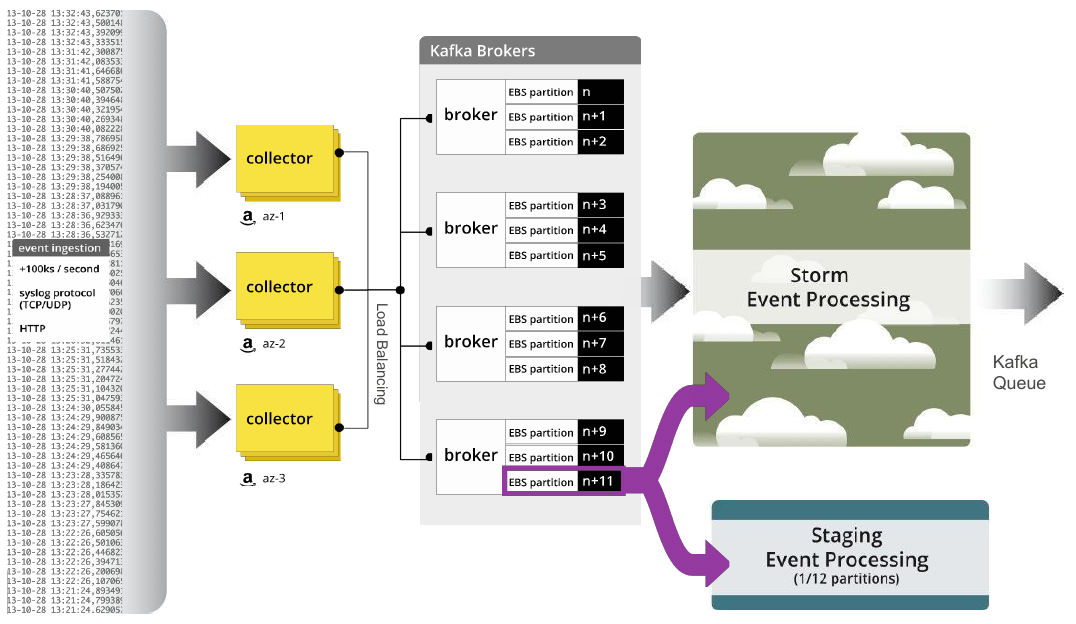
My role involved prototyping, system architecture and design, software implementation, performance tuning, and ensuring the design and implementation remained coherent.
As a team lead I placed a strong emphasis on testing, both at the unit-test level, and through continuous integration. I was also responsible for tracking progress, bug management, working with Product Management, and ensuring quality remains high. I was closely involved with hiring as the team grew to 5 developers.
I also worked closely with the Operations team, advising on best practices, preparing deployment guides, and resolving system outages. I also contributed to the company blog, participated in meetings with potential investors, and represented Loggly at trade shows and developer conferences.
Collector
I personally designed and implemented the 2nd-generation Collector. Written in C++, the Collector is an event-driven, multi-threaded, high-performance data-ingestion process, responsible for receiving all data destined for the Loggly system. Built to scale horizontally, and using the Boost ASIO framework, the Collector supports UDP, TCP, TLS, and HTTP, traffic.
Kafka-Storm Data Pipeline
Along with the Infrastructure team, I designed and coded much of the Kafka–Storm-based data pipeline. This involved work in Java and Clojure, and also involved coding many monitoring and maintenance tool suites, which were mostly written in Python. The pipeline also interacted heavily with many other AWS services such as S3 and RDS.
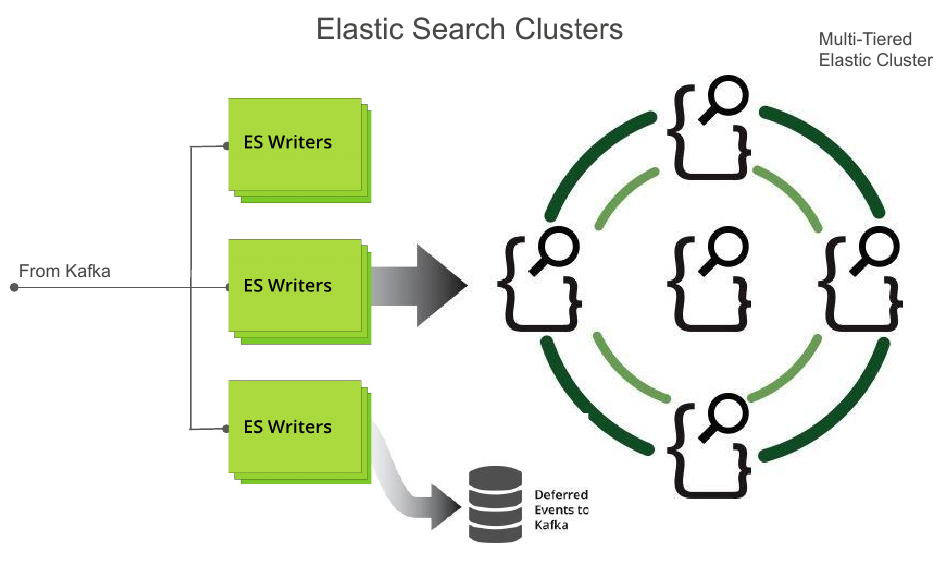
Real-time Indexing and Search with elasticsearch
I was heavily involved with the design and implementation of the near real-time indexing pipeline, including cluster maintenance, index-management, interacting with elasticsearch, and performance and correctness testing.
Development and Test System
During the development of Loggly’s 2nd-generation system, I deployed, operated, and maintained, a large, multi-EC2-node ingestion pipeline, and elasticsearch cluster. This system acted as our main test-and-soak deployment, and was run at close-to-production standards. It allowed us to flush out many issues in our system and code before launch, and gave me a deep appreciation of the challenges of running large, high-performance, distributed systems — and keeping them running.
Riverbed Technology
San Francisco, CA
Engineering Manager, Cloud Services Development
2011 – 2012
Member of the Technical Staff
2007 – 2011
Riverbed makes WAN optimization equipment (known as Steelheads), develops software-based Cloud services, and advanced storage appliances. Steelheads are Linux-based appliances that allow enterprises to greatly increase the effective speed of their WAN links and remote storage. I joined Riverbed as a Development Engineer and, during my time there, progressed to managing a development team of 5 engineers, which designed and implemented Riverbed solutions for Cloud Computing infrastructures. I also contributed regularly to the corporate blog.
While at Riverbed, I had a deeply technical role, personally designing, implementing, and debugging, major elements of Riverbed’s next-generation products. I was responsible for developing high-level designs and REST APIs, writing specifications, implementation in C, C++, & Python, ensuring that the software developed by my team was of high-quality, always underwent unit-level & system-level test, and that the design and implementation remained coherent. I was also responsible for developing the team and tracking project progress. In addition I managed the migration to virtual development environments, and an upgrade to Python 2.6 and Django 1.3.1.
Providing support to the corporate technical Sales and Support organizations is a critical responsibility. This involved writing troubleshooting guides, making presentations during new product roll-out, working with customers during fields trials, and putting processes in place which would allow Support to debug issues in the field.
Riverbed Cloud Portal

I was the lead member of the Riverbed Cloud Portal design and development team. Developed primarily in Python, the Cloud Portal is an Enterprise-grade web Portal, which allows Riverbed customers to provision, manage, and license their Riverbed Appliances and Services in the Cloud. As a result of this development, I gained significant experience with Amazon Web Services (AWS) and other Cloud Computing technologies, basic SQL, designing for scale, various Web Application Frameworks, both back-end and front-end technologies, Apache web server, and general project release and bug management.
I regularly worked with Riverbed’s IT department assisting with deployment of the production Portal and also deployed and manage a Dogfood Portal for internal use. I consider documentation an important part of a professional engineer’s role, and authored detailed deployment documentation for the Portal, as it is deployed in the AWS Cloud (including configuring EC2 Instances, Load-Balancers, EBS storage, and RDS databases). I also brought Support and Sales personnel up to speed on new releases, and educated the relevant parties on best-practices for the Portal. The Cloud Portal was first brought online in November 2010 and I oversaw multiple upgrades of this system.
The Portal is a mission-critical component of both the Steelhead Cloud Accelerator and Cloud Steelhead solutions.
Steelhead Cloud Accelerator
I led a technical team responsible for all configuration and management software for the Steelhead Cloud Accelerator. The award-winning Steelhead Cloud Accelerator, developed jointly with Akamai, allows enterprises to greatly improve the delivery of business-critical data and content from a SaaS provider’s public cloud infrastructure. It was launched in February 2012.
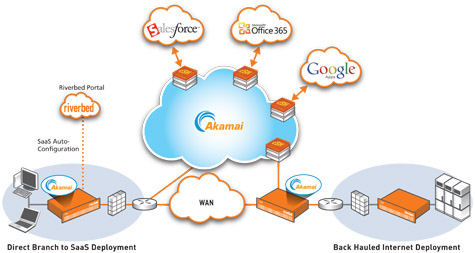
I designed and implemented, mostly using Python, much of the new Riverbed Cloud Portal functionality required by the Steelhead Cloud Accelerator. The Portal acts as a central co-ordination point for all customer Steelheads acting as Cloud Accelerators, communicates with the Akamai infrastructure on behalf of our customers, and allows Riverbed’s customers to configure and manage their Accelerator deployments. As a result of this project, I greatly increased my knowledge of X.509 SSL & public certificate management techniques, as well as Software-as-a-Service deployments. I also wrote much of the new software (written in C and bash) running on the Steelheads. Once upgraded to the new software, the Steelheads can participate in the Cloud Accelerator service, allowing end-users much higher performance when connecting to the SaaS Platforms such Office 365 and Saleforce.com. The Steelhead Cloud Accelerator was launched in February 2012.
Cloud Steelhead Development

During my initial period with the Cloud Services team, I was a lead technical member of design team which developed the Riverbed Cloud Steelhead. In addition to Cloud Portal development, my responsibilities included bringing up Riverbed’s flagship product in both the AWS Cloud and ESX-based private Clouds, all the while ensuring it had the same reliability and ease-of-use when running in those Cloud environments. This work involved changes to the appliance software (C, Python, and bash scripts), the build system, and subsequent release generation and management of the Amazon Machine Images (AMIs) and ESX Open Virtual Format (OVF) images. The Cloud Steelhead was launched in November 2010.
Riverbed Services Platform

During my first two years at Riverbed I was a member of the Riverbed Services Platform (RSP) team. The RSP allows Riverbed’s customers to run up to five virtual machines on their Steelhead appliances. This work involved significant C code, Python, and bash scripting to integrate VMware Server 2.0 with the Steelhead’s existing software, as well as integration with the source-control and build process. The RSP solution has many moving parts, so I also created a test framework that automatically performed complete system testing every night, and reported results each morning. I gained significant experience with virtualization technologies through my work on RSP.
The solution was launched in 2008, and it has become an important differentiator for Riverbed. A very successful product, 20% of Riverbed Steelhead appliances now ship with RSP licenses.
TiVo
Alviso, CA
Member of the Technical Staff
2004 – 2007

I was a key member of the system software team that developed TiVo’s flagship Linux-based Series3 High-Definition Digital Video Recorders (DVRs). As part of this team I developed API definitions, implemented drivers and coded kernel & user space code (in C and C++) for tuners, demodulators, related MPEG input subsystems and the media pipeline.
I also performed board bring-up of multiple tuner/demodulator & encoder boards and provided software support for hardware evaluation of both analog (NTSC) and digital (ATSC/QAM) components. My work also involved implementing and debugging other areas of system code including copy protection policies, output display controllers, MPEG stream processing, audio output and video encoder performance.
Successful CableLabs certification was a critical requirement for these DVRs and I provided software support for this testing. As a result I gained significant experience working with an industry Standards body. The DVRs shipped in September 2006 and July 2007.

Since TiVo supports a diverse user base of more than 3 million units, I was heavily involved with performance improvement, bug triage and risk evaluation across multiple product lines.
During development I also acted as main liaison for an off-site development contracting firm. This involved assisting with development environment setup, driving bug resolution and inter-company communications.
At TiVo I gained extensive experience ramping up and working on a large and mature code base which had complex branching, Perforce-based source control and build strategies.
TiVo also relies heavily on code developed by semiconductor vendors, and this requires careful integration of large code drops into TiVo’s source control system and facilitating reverse drops. I performed many of these merges and sent patches back to these vendors.
Skystream Networks
Sunnyvale, CA
Embedded Software Engineer
2000 – 2004

At Skystream Networks I gained a lot of experience with MPEG systems and digital broadcast technologies, as well as embedded software and digital hardware.
The majority of my time at Skystream was spent designing, developing and debugging high performance embedded software and BootROM firmware for Skystream Networks’ flagship Mediaplex product, an x86 VxWorks-based MPEG video/audio and IP router. I performed board bring-up with the hardware engineers and personally wrote 30,000+ lines of C and assembler on a multiprocessor PPC4xxGP RISC platform. The router was released June 2002.

I also designed and coded a Linux device driver for the same digital video hardware. (Loadable kernel module on kernel 2.14-20, Pentium III platform, written in C). The driver was completed in Q4, 2003 and meant the board could be supported on any host system running a suitable Linux kernel.
Skystream also wanted to release an MPEG2 encoding solution for the Mediaplex so I ported Dolby Digital AC3 audio encoding software to a multiprocessor Motorola DSP 563xx platform, with the video encoding performed by a separate SoC. I performed board bring-up with Skystream hardware engineers and then went on to design and write the I/O software for the entire board. This work was carried out in C and assembler. During the final stages of this project I coordinated successful product certification with Dolby engineers. The encoder was released in Q3 2003.

During encoder evaluation I created a custom MPEG2 & MPEG4 encoder test-bed suite using MS Visual Studio and DirectX SDK. The test suite was released for internal use during Q4 2003. It allowed us to gather PSNR measurements for various encoder settings, which allowed us to make trade-offs between encoder quality and bandwidth requirements.
During my initial days at Skystream I also created a test bed suite for Skystream’s Edge Media Router, using Microsoft Visual C++ and MFC. The test bed was released to the manufacturing department in November 2000.
Nortel Networks
Galway, Ireland
Software Engineer
1997 – 2000

At Nortel I developed and debugged real-time embedded software (written in C) for a pSOS-based DECT wireless telephone system. I also assisted with in-house trials of various handsets. The DECT solution released Q3 1998.
I also designed and implemented MS Windows applications for value-add to the DECT project. This software was written in Visual C++ and Visual Basic. I authored numerous system test plans and technical trials during product roll out and co-ordinated the in-house trials.
I submitted one patent application related to telephone user interfaces on behalf of Nortel Networks. This was filed as Patent Pending # 09/557,107; filed: April 24th 2000. “Improvement of dialed strings.”
Education
National University of Ireland
Galway, Ireland
B.Sc. in Applied Physics and Electronics
1993 – 1997
Graduated summa cum laude (1st class Honours).
Subjects included Computer Science, Mathematics, Mathematical Physics, Classical Mechanics, Electromagnetism, Electronics, Optics, Solid States Physics, and Quantum Physics.

I was awarded the Nortel Networks prize for my final year project – An Experiment in Virtual Reality. The project involved the construction of a data glove, which I connected to a PC system, and the development of software on the PC. This allowed the user to manipulate a virtual world, which existed only inside the computer, through the glove alone. The software was written in C using the Borland compiler.
I was subsequently offered, and accepted, a design position at Nortel Networks.