![]() Another interesting paper came my way, thanks to the Morning Paper mailing list. Nines are Not Enough:Meaningful Metrics for Clouds discusses a topic that I deal with regularly in my role at Google.
Another interesting paper came my way, thanks to the Morning Paper mailing list. Nines are Not Enough:Meaningful Metrics for Clouds discusses a topic that I deal with regularly in my role at Google.
SLIs, SLOs, and SLA are easy to discuss in a general sense, but surprisingly subtle to put into practise. This paper, authored by Google engineers, explores why this is so, and offers a new framework for thinking about them.
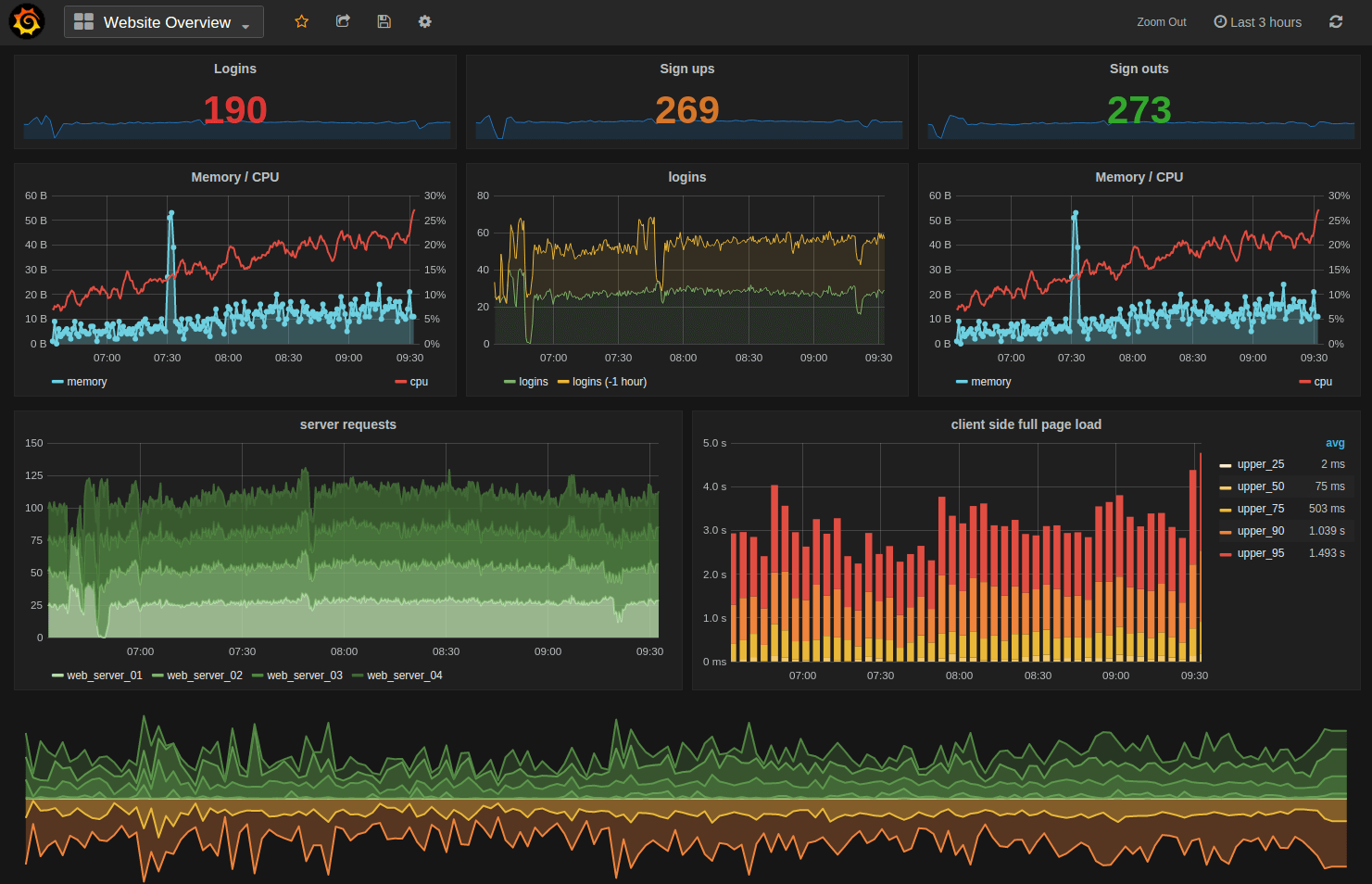 Monitoring — the measurement of your system, the gathering of telemetry, and alerting when it behaves anomalously — is
Monitoring — the measurement of your system, the gathering of telemetry, and alerting when it behaves anomalously — is  In every field there is a question that, while it sounds interesting, betrays a naiveté and lack of sophistication.
In every field there is a question that, while it sounds interesting, betrays a naiveté and lack of sophistication.
