 LowEndBox has written a good blog post on rqlite, the lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. You can check it out here.
LowEndBox has written a good blog post on rqlite, the lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. You can check it out here.
Tag Archives: operations
From Rackspace to GCP
Talking Audit Logging on Google Cloud Platform
 I recently took part in the GCP Podcast, along with my colleague Oscar Guerrero. On the podcast we spoke about Audit Logging, which is a critical security feature of GCP.
I recently took part in the GCP Podcast, along with my colleague Oscar Guerrero. On the podcast we spoke about Audit Logging, which is a critical security feature of GCP.
Be sure to check out the podcast episode.
Moving to HTTPS with Let’s Encrypt
 After reading an interesting paper on Let’s Encrypt, I finally decided to switch this website over to HTTPS. I was really impressed with how smoothly the whole conversion went.
After reading an interesting paper on Let’s Encrypt, I finally decided to switch this website over to HTTPS. I was really impressed with how smoothly the whole conversion went.
With the help of Certbot from the EFF, it took less than 5 minutes and ran without error. Very impressive!
Logging and Monitoring systems are hard to code
This is a post following up on my Monitorama Baltimore 2019 talk.
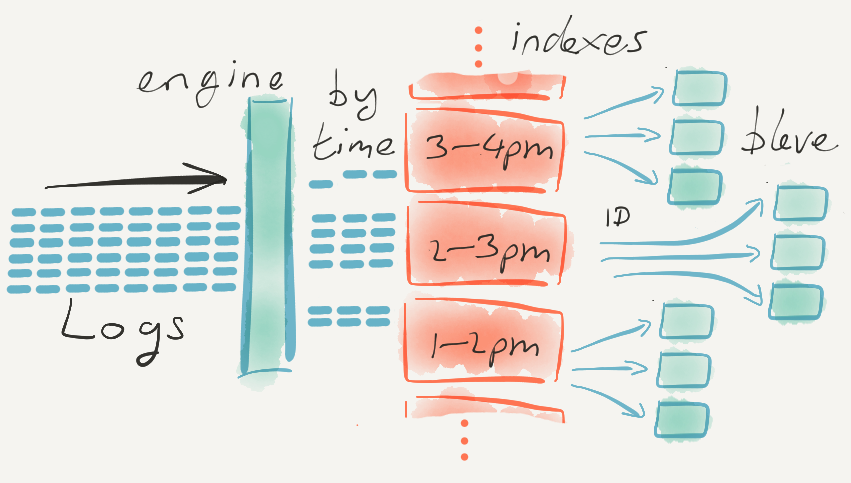
Logging and Monitoring systems — Observability Systems, if you prefer — often seem to struggle to meet the needs of their users.
Continue reading Logging and Monitoring systems are hard to code
Observing Observability at Devopsday
 It was great to speak at devopsdays in Galway. I really enjoyed bringing my recent Monitorama 2019 talk to my home town.
It was great to speak at devopsdays in Galway. I really enjoyed bringing my recent Monitorama 2019 talk to my home town.
A video of the talk has now been posted.
devopsdays Galway
I will be joining my colleague from Google, Nathen Harvey, to speak in Galway at devopsdays on November 18th and 19th.
I’m really looking forward to returning to my home town, and bringing my Monitorama Baltimore 2019 talk to the conference.
Observing Observability
Monitorama Baltimore 2019![]() was a great experience, and I really enjoyed the opportunity to speak. I spoke about why Observability and Monitoring sytems struggle to meet their goals, and why they are so hard to build.
was a great experience, and I really enjoyed the opportunity to speak. I spoke about why Observability and Monitoring sytems struggle to meet their goals, and why they are so hard to build.
The slides and video of the talk are now available.
Monitorama Baltimore 2019
![]() I have been accepted to talk at Monitorama Baltimore this year. I’ll be speaking about my experience building Observability systems at many different companies, and how might those lessons be applicable to other teams and groups.
I have been accepted to talk at Monitorama Baltimore this year. I’ll be speaking about my experience building Observability systems at many different companies, and how might those lessons be applicable to other teams and groups.
Check out the full schedule.
Continuing the WordPress bring-up on GCP
![]() Following up on my earlier post, it has been pretty straightforward to so far to migrate this blog from Rackspace to GCP. It’s going pretty much as expected, but the architecture is going to be slightly different than I initially thought.
Following up on my earlier post, it has been pretty straightforward to so far to migrate this blog from Rackspace to GCP. It’s going pretty much as expected, but the architecture is going to be slightly different than I initially thought.