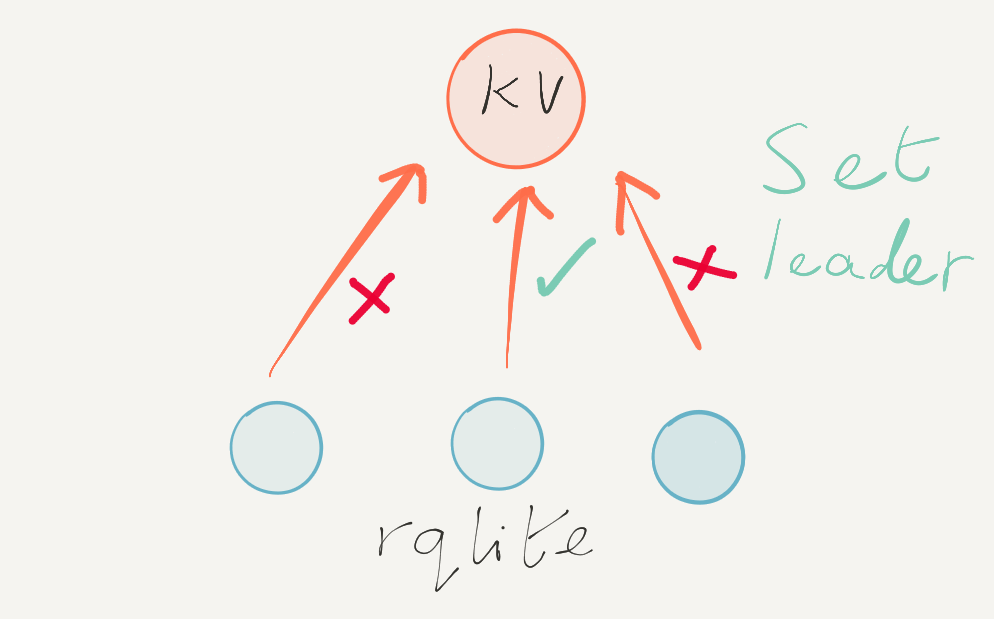
![]() During the development of rqlite 8.0, a surprising behavior revealed itself through an unexpected venue: AppVeyor, the Continuous Integration (CI) system I employ for Windows testing.
During the development of rqlite 8.0, a surprising behavior revealed itself through an unexpected venue: AppVeyor, the Continuous Integration (CI) system I employ for Windows testing.
And even more unexpected was the resolution of previously unreliable unit tests.