 This September I’ll be speaking at GopherCon 2023. The conference takes place in San Diego, and I’ll be giving a talk on Building Distributed Systems in Go using the Raft consensus protocol. Much of my presentation will be based on my experience building rqlite.
This September I’ll be speaking at GopherCon 2023. The conference takes place in San Diego, and I’ll be giving a talk on Building Distributed Systems in Go using the Raft consensus protocol. Much of my presentation will be based on my experience building rqlite.
Tag Archives: distributed systems
rqlite upgraded to SQLite 3.42.0

rqlite now supports PowerPC, MIPS, and RISC
![]() rqlite is a lightweight, open-source, distributed relational database written in Go, utilizing SQLite as its storage engine.
rqlite is a lightweight, open-source, distributed relational database written in Go, utilizing SQLite as its storage engine.
rqlite v7.19.0 is out now, and there have been quite a few auto-clustering improvements a bug fixes added. In addition, through the magic of Go cross-compilation support, rqlite can now run on a much wider variety of CPU architectures.
You can download the release from GitHub.
rqlite 7.14.2 released
 rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine.
rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine.
7.14.2 adds various bug fixes and improvements. Most of the rqlite source code was also run through GPT-4, and many of its suggested improvements were incorporated into this release.
You can download the release from GitHub.
9 years of open-source database development
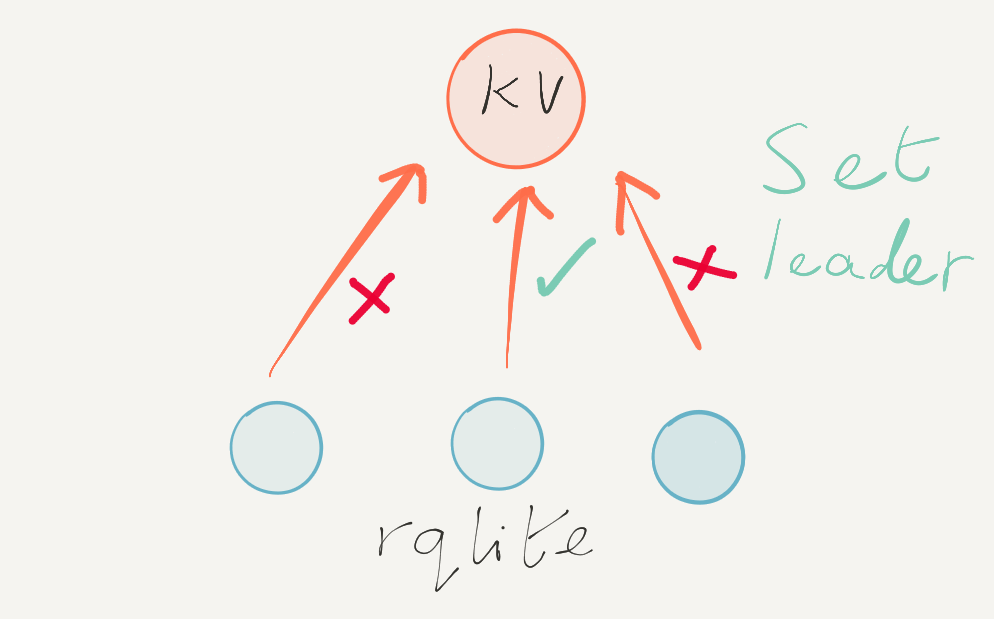 rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine.
rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine.
I’ve been developing rqlite since 2014 and its design and implementation has evolved substantially during that time — and the design docs tell the story of what worked, and what didn’t. So what can we learn about distributed database design, from watching rqlite change over the years?
Continue reading 9 years of open-source database development
Creating rqlite 7.14.0 with GitHub Copilot
 rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. 7.14.0 has been released and adds comprehensive support for Mutual TLS.
rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine. 7.14.0 has been released and adds comprehensive support for Mutual TLS.
What makes this release of rqlite different is that much of the TLS support was written using GitHub Copilot.
rqlite 7.13.0 released

rqlite 7.12.0 released
rqlite 7.11.0 released

rqlite 7.10.0 released
 rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine.
rqlite is a lightweight, open-source, distributed relational database written in Go, which uses SQLite as its storage engine.
Replicated, a company which helps software vendors ship software to end users, recently migrated from PostgreSQL to rqlite. Along the way their input substantially helped improve how rqlite runs on Kubernetes — and as a result rqlite 7.10.0 is out now. This latest release is also running an upgraded version of SQLite.